SQL indexed views are incompatible with Dynamics GP

See similar post: sql filtered index are incompatible with dynamics gp
Indexed views with Dynamics GP?
– well I’ve been there and I have seen others attempt the same. The Dynamics GP database and application are not really compatible with SQL indexed views. To help out those searching around this subject I thought I should write up our experience.
What is an indexed view?
An indexed view is a SQL database view that has had an index applied to it. This sounds obvious, but the important thing to realise is that the index will be materialised as an index on disk. Think of it as another table created on disk representing the data held in the view, this is why it is quick to get the data if it is summary data. This index "table" is maintained whenever the data that it covers is altered. So it is easy to imagine that indexed views are great for creating summaries, filtered views of data that cross multiple tables, as they will keep track of changes automatically and update the index "table", thus keeping the data "in-sync" with the data in the various tables that it derives from. As the data that represents the SQL view has been pushed to disk and persisted there, querying that summary data is lightweight and quick, because the work has already been done to process the data when it was stored, pre-joined between tables and/or summarised, rather than the database engine having to do all that work on the fly for each query as the query is ran.
However, there is a downside. When (any) index is created, you pay a price for the benefit of fast data recall when reading, by suffering with slightly longer writes times and those longer writes lead to longer living locks on the data and then this can lead to blocking. This may cause issues with performance in some circumstances. The extra writing is because the data held in the index "table" that represents the view needs to be maintained (updated) whenever any of the data underpinning that view changes. Depending on the workload sizes of tables, IO performance etc, this may be significant work if large numbers of records are updated at once. Again as with any SQL index, it takes space on disk too. For large wide views over large tables this may be a consideration too bloating storage and the knock on consequences that brings.
One of the most frustrating matters when working with indexed views is that there are a whole heap of constraints and restrictions around what is permitted in the query that forms them. For example, when using GROUP BY, it must contain the function BIG_COUNT(*) as a column and various database settings restrictions can apply too (there are many, many more). This means when designing the simplest views SQL compile errors warning that it is not possible to do "this and that” frequently cause annoyance. It is very obvious why this is the case when you think about it. It is due to the fact the data is persisted to disk, so it needs to be unchanging to store it, thus any SQL function used by the view has to be deterministic -aha, no “getdate()” function! It is surprising how often this will catch people out. I could go on and on about the restrictions and requirements of indexed views, but just go try making one and you’ll discover the pain yourself, then go read up the documentation to realise how much there is to it!
Another example below are the SQL SET OPTIONS that are required by SQL indexed views…

Using indexed view with Dynamics GP
Professionally we use indexed views a lot in our applications for the speed of access and real time integrity of summary data they offers, so sooner or later a GP admin or GP developer decides they would quite like to use an indexed view... -then it all ends in tears, let us see why…
WITH SCHEMABINDING
This is the first problem. To build an index view the view must use SCHEMABINDING. This locks the database schema and the view together. Unfortunately this may then cause issues with application updates. When Dynamics GP is updated for a service pack or upgrade, sometimes the tables or other database objects may need to be dropped and recreated. This happens during the upgrade process, however if the object that is to dropped is schema bound, then the upgrade script will not be allowed to do what it wants, causing the upgrade to fall over. Hence if indexed views have been bound to the GP tables this is a real risk when a site comes to do an upgrade. Obviously if the person performing the upgrade was aware, then they could drop the view and recreate it after the upgrade, but in real life the knowledge is lost as employees leave or contractors move on causing upgrade pain.
The second problem is more terminal. Let's try it and see what happens if we create a view over the sales order header and lines to speed up the number of sales lines by country that and not voided in historical transactions. Create the view on a non-production database like this…
SET NUMERIC_ROUNDABORT OFF;
SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT,
QUOTED_IDENTIFIER, ANSI_NULLS ON;
-- We must schema bind
IF OBJECT_ID ('SalesVoidedLinesSummary', 'view') IS NOT NULL
DROP VIEW SalesVoidedLinesSummary ;
GO
CREATE VIEW SalesVoidedLinesSummary
WITH SCHEMABINDING
AS
SELECT COUNT_BIG(*) Cnt,
SOP30200.SOPTYPE,
SOP30300.CCODE as Country
FROM
dbo.SOP30200
JOIN
dbo.SOP30300 ON SOP30200.SOPTYPE=SOP30300.SOPTYPE AND SOP30200.SOPNUMBE=SOP30300.SOPNUMBE
WHERE
SOP30200.VOIDSTTS=0 --Not Voided
AND SOP30200.SOPTYPE IN (1,2)
GROUP BY SOP30200.SOPTYPE, SOP30300.CCODE
GO
Then create the indexed view by adding the index. - REMEMBER I SAID NO PRODUCTION DATABASES WITH THIS LITTLE EXPERIMENT!
--We materialise the view by creating an index on it
CREATE UNIQUE CLUSTERED INDEX IX_SOP30200SOP30300VoidSummary
ON SalesVoidedLinesSummary (SOPTYPE, Country);
GO
We can now query the view data like so..
SELECT * FROM SalesVoidedLinesSummary where SOPTYPE=1 AND Country='PT'
and directly before we created the view with this…
SELECT COUNT_BIG(*) Cnt,
SOP30200.SOPTYPE,
SOP30300.CCODE as Country
FROM
dbo.SOP30200
JOIN
dbo.SOP30300 ON SOP30200.SOPTYPE=SOP30300.SOPTYPE AND SOP30200.SOPNUMBE=SOP30300.SOPNUMBE
WHERE
SOP30200.VOIDSTTS=0 --Voided
AND SOP30200.SOPTYPE = 1
AND SOP30300.CCODE='PT'
GROUP BY SOP30200.SOPTYPE, SOP30300.CCODE
...and we find that from not having the view to having the view we have dramatically reduced the query time as shown below. I’m not sure about the integrity of those figures but this isn’t a discussion around query optimisations, just accept that indexed views solve performance problems.
| Total execution time without view: | 17390 |
| Total execution time with view: | 505 |
In production
So developer or IT pro after testing that out on the test company database says, “great, now lets create it on the production database as that worked like a charm”, and then goes to login to GP and create a sales order having created the view…
...to then get the dismay of the error that follows...
“An edit operation on table ‘SOP_Master_Number_SETP’ failed. A record was already locked'.”

and
INSERT failed because the following SET options have incorrect settings ‘QUOTED_IDENTIFIER, CONCAT_NULL_YEALS_NULL,ANSI_WARNINGS’. Verify that SET options are correct for use with indexed views and”…

… then starts the support calls flowing in from the users!
So why we can’t have nice things?
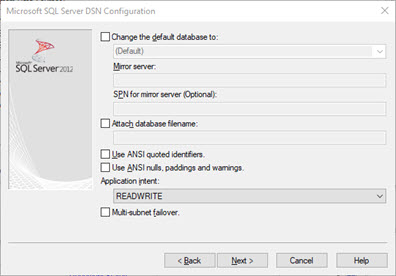
Go back up in this post, as you saw in the graphic, that there are certain SQL SET options required to make indexed views work. Sadly these are not compatible with the SET options required to make Dynamics GP work shown below! -thus the application breaks, simple as that! If those phones are still ringing from your users right now, then just simply drop the view and your users will be happy again.
We did play around a bit but never found a solution to this issue, but if you have a work around do let me know.
References
Mariano Gomez has a nice post about why this is required by Dexterity to make GP run correctly in this post:
Microsoft SQL Server DSN Configuration
Microsoft - Creating Indexed Views
Gavin wrote this which inspired me to document the issue before others fall into it...