Local hosted models
It is fun to download Ollama and run an AI model locally on your laptop or desktop computer, even without an Internet connection. It teaches us to think about model selection even in cloud AI.


At the beginning of my journey learning about AI, I had assumed the ChatGPT experience of interacting with AI models, through a web browser, over the Internet was the only way they were available. I thought these AI models are on massive behemoths of machines only available to "big tech." I did know there were APIs to access these models for our own applications, but I thought big servers held by big tech were hosting and running these AI models.

Certainly, when it comes to large AI models, there is some truth to this picture of the architecture. But for smaller models, it is also totally viable to download the AI model onto a laptop, or even better, a machine with a good GPU(s) in it, and run the model locally on your own little laptop/desktop/server. 🤯
Locally hosted AI needs no internet, is secure & is "free"
Hey, running AI models locally is super exciting, and it instantly mitigates concerns you or your customers may have regarding running sensitive corporate data through cloud AI services. It also means AI processing is possible when not connected to the internet. The ability to run AI locally with no data connection to the Internet is also why there is a flurry of activity around micro-sized AI models. These tiny models will run on mobile phones and similar small devices for very specific uses. It is obvious that specialist Neural Processing Unit (NPU) chips will be fitted as standard to desktops, laptops, and mobile devices in the future to make efficient running of AI workloads possible locally. More efficient means faster, which is a big hurdle in use.
The other benefit of running locally with open-source models is cost—there is no $ meter running when running AI on a local machine, other than the electricity burnt. The costs quickly become significant when running large production volumes of data through the mainstream AI platforms, such a Zapier, Make.com etc. Running on many small local models starts to make sense very quickly, if those models can be trained, fine-tuned, to give the desired results.
The downside of local: speed and model sizes
Although local models are exciting, before getting too excited about running AI for free locally, the speed and small size of local models do limit the use of them to well defined tasks where the models can be fined tuned to get the results required. The small model size limits the diversity of tasks they are capable of. Lucky that in business, individual tasks are often limited in scope, so it is less of a problem than one would imagine. It looks like an increasingly popular approach to AI is to use lots of small targeted models voting together and collaborating rather than a super-sized model.
Regarding speed, a lot of "back-office" processing does not need to happen in real time, especially in the SMB/SME business settings I've encountered. Local, small models are fine for processing a slow stream of emails or processing a flow of new records being created in the database in non-real time. The volumes of data in an SMB/SME business tend to be smaller (depending on the nature of the business). It is also possible to scale out these models, despatching work loads to a large number of small models to get parallel processing of the workload in place.
Local AI models are in my experience good for processing as a background activity, places where it is okay to have an AI agent working its way through a queue of work.

Maybe this is making local AI models sound super slow, but really it is not that bad, I am pointing out performance, as it is helpful to have appropriate expectations of them. Small models are actually faster than large models, but the real constraint is the hardware, it really matters, so running on standard laptop, it will feel slow, however with some careful choices in hardware speeds will quickly improve. This is difference between running AI models on laptop for development locally, and then putting that on production hardware, where they should perform well.
Keep it local: AI for distributed AI & IoT
Local models can also be effective for distributed AI. The Internet of Things (IoT), where intelligent small sensors autonomously report back or act on instructions, is an excellent candidate for local AI solutions. Adaptive sensors can learn from cameras or other feedback, as machines evolve over the cycles of a production process. Factors such as temperature or variations in material quality between batches can affect production lines, making local AI invaluable. IoT isn't limited to mass manufacturing; it has applications across a wide range of industries.
Distributed AI models held locally can also aid compliance by keeping data in silos, ensuring data security for legislative or confidentiality reasons. Personally, I find this area particularly fascinating and expect significant growth in the near future. These distributed models are, importantly, small models, designed for efficiency and local deployment, tuned for specific tasks.
Working with local models raises awarenes of model choices for cloud AI too
As working with local models encourages the use of smaller, more compact models (as they use less memory and consume less processor), it also reminds us as developers—even when we are working with cloud-hosted AI—that model choice is important. As developers, we tend to grab the biggest, most powerful, new shiny hammer to hit a problem with. In fact, a smaller, lighter-weight hammer that can be held for longer and more easily brandished could well be more appropriate for the task. This has real implications in cloud-hosted AI, where some of these small models are super cheap to consume compared to the latest super-sized models. There is another post I have made on model size and choice.
Super quick & simple to try local AI
It is so simple to give running local AI a go—see how this could be loaded onto your enterprise server and used for discreet, scoped tasks very effectively.
Meta have the Llama 3.1 model, which is impressive and very much up to handling small AI processing tasks. It is also very simple to get running on your machine, running locally, even without an Internet connection!
Ollama
To run models locally, we can employ Ollama.
Ollama allows you to host and operate AI models on your local machine. It feels like a host application that you will later load the AI model into. In some ways, it is analogous to Docker and containers. The model is the container that is loaded into Ollama to host and run. Ollama makes the selected and downloaded model promptable—if that is even a term? 🤔
A number of models may be downloaded into the host and run locally, such as Llama 3, Gemma, Mistral, and phi3:mini. Ollama abstracts all the hosting away, so you don't have to worry about anything other than choosing a prompt to use. Ollama will even automatically try to use any GPUs on the machine to improve performance. Plenty of RAM is required to run the models, but most modern laptops would be fine with the smaller models.
Setting up
Navigate to: https://ollama.com/download
Download for your computer platform and run the installer. For Windows, it goes like this...
Click install and wait... wait... then wait...
Once installed, Ollama will be found running in the Windows system tray, typically next to the time on the bottom bar of Windows.
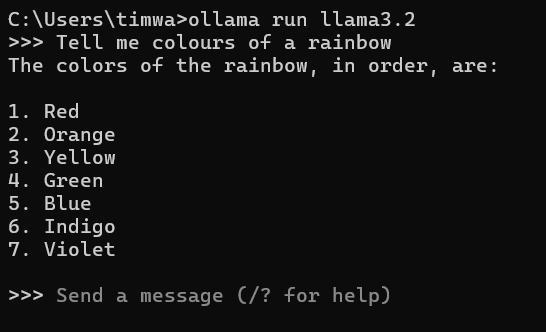
I'm only covering a quick start here, so type the following command into the Windows command window:
ollama run llama3.1
Really, that is all there is to it! The model can be prompted right there in the command line once it gets to this message, after it has downloaded the model. The model download is cached, so it is a one-time hit.

After prompting the AI, you can see the answer is returned to the console as shown.
Ollama library/registry
There is a vast list of models available from the library, to find the model name look it up from the Ollama library page.
To pull the model from the library/registry use the pull command. The following pulls the Microsoft 3B parameter model.
ollama pull phi3:mini

Here are examples of some of the many models:
| Model Name | Company |
|---|---|
| llama3.2 | Meta |
| llama3.1 | Meta |
| gemma2 | |
| qwen2.5 | Alibaba |
| phi3.5 | Microsoft |
| nemotron-mini | NVIDIA |
| mistral-small | Mistral AI |
| mistral-nemo | Mistral AI and NVIDIA |
| deepseek-coder-v2 | DeepSeek |
| mistral | Mistral AI |
| mixtral | Mistral AI |
| codegemma | |
| command-r | Anthropic |
| command-r-plus | Anthropic |
| llava | Microsoft |
| llama3 | Meta |
| gemma | Google DeepMind |
| qwen | Alibaba Cloud |
| qwen2 | Alibaba |
| phi3 | Microsoft |
| llama2 | Meta |
| codellama | Meta |
| nomic-embed-text | Nomic AI |
| mxbai-embed-large | mixedbread.ai |
| starcoder2 | BigCode |
| phi | Microsoft Research |
| deepseek-coder | DeepSeek |
| qwen2.5-coder | Alibaba |
| yi | 01.AI |
| zephyr | Hugging Face |
| llava-llama3 | Meta |
| snowflake-arctic-embed | Snowflake |
| mistral-openorca | Mistral AI |
| starcoder | BigCode |
| codestral | Mistral AI |
| granite-code | IBM |
| codegeex4 | Zhipu AI |
| all-minilm | Microsoft |
| nous-hermes2 | Nous Research |
| wizardlm2 | Microsoft AI |
| openchat | Anthropic |
| aya | Cohere |
| codeqwen | Alibaba |
| stable-code | Stability AI |
| mistral-large | Mistral AI |
| reflection | Anthropic |
| stablelm2 | Stability AI |
| glm4 | Tsinghua University |
| neural-chat | Intel |
| llama3-chatqa | NVIDIA |
| moondream | Vikhyat Korrapati |
| sqlcoder | DefogTech |
| deepseek-v2 | DeepSeek |
| starling-lm | CarperAI |
Now lest run the model we just pulled, we run the model with
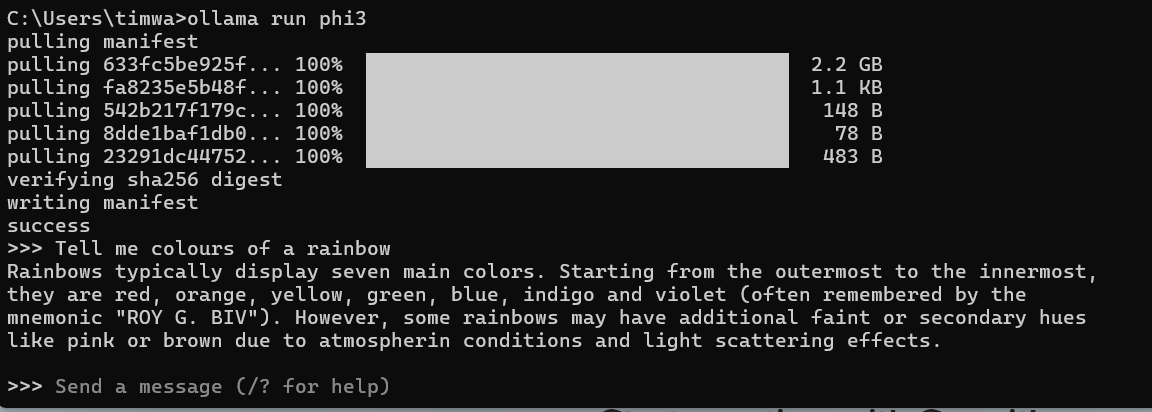
ollama run phi3
Notice in the run command we didn't specify the version :mini after the model name, this is not required if there is only one model by that name. Next lets use the same rainbow prompt on phi3 as we used before. This time we get a much more verbose answer than that llama3.1 gave us, see below.
This is just to get you going locally, but the following blog gives much more comprehensive information about how to further configure Ollama, changing data folders, manipulating GPU usage, etc.
You will find this blog post offers much more detailed information about configuring Ollama:
https://medium.com/@researchgraph/how-to-run-ollama-on-windows-8a1622525ada
Talking to local Ollama models from C#
Play with the model and see how much you can do with a very small model—it’s interesting how much they can achieve and makes you realise that some tasks do not require those massive online AI models.
Next post will cover how to programmatically access the local model, prompt the AI, and get responses by using Semantic Kernel and C# for .NET.