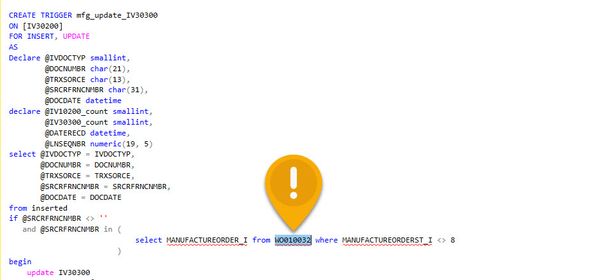
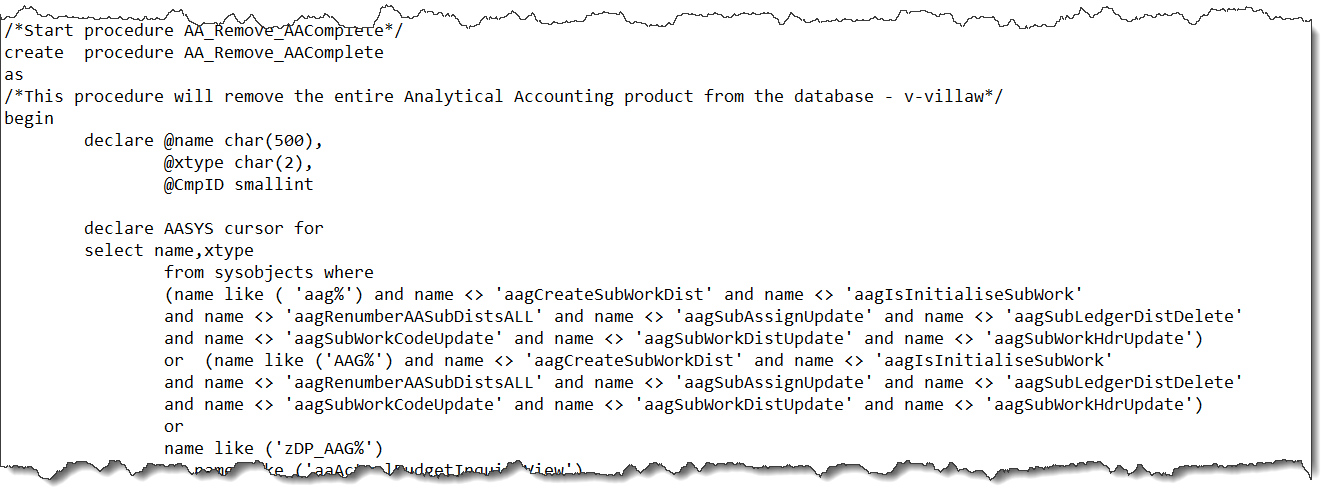
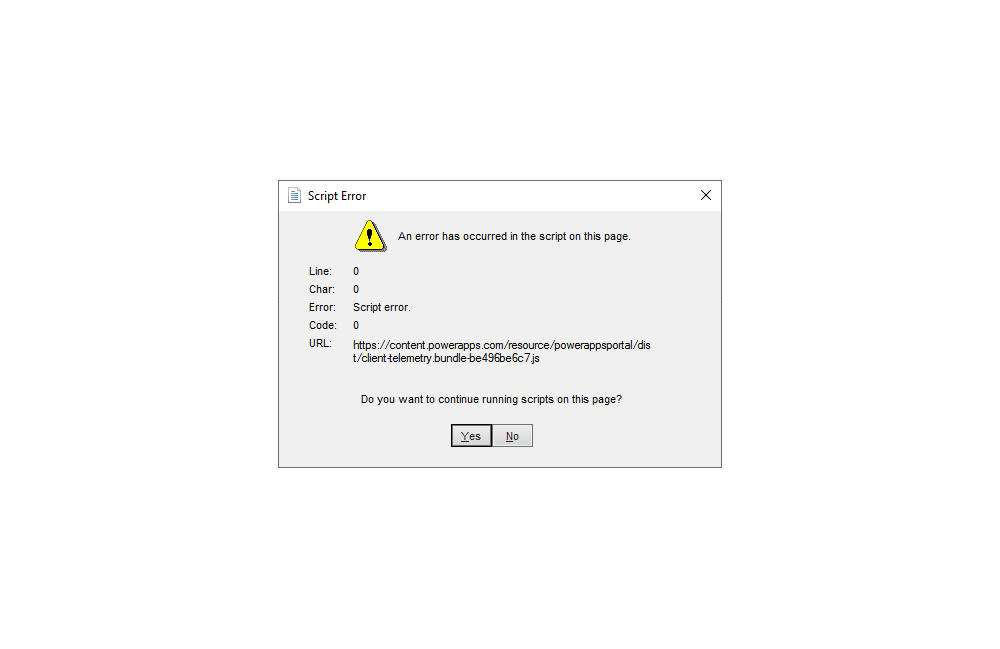
Having renamed the entire Analytical Accounting database objects in the company database, using a script derived from KB915903 eConnect started immediately creating errors so I went to investigate.
Invalid object Name AAG20000
Having opened up the eConnect scripts to see what was going on (taProcessAnalytics, taCreateSOPDistributions, taAnalkyticsDistribution among others), it